- Research questions:
Our FloPo group project focused on the following research questions; can we identify polarization within media based on time regardless of its type; how did the articulated strategies of the campaigns resonate within news journalism and social media; were there any key differences between the Tahdon2013 and the trans law campaigns, and if so, what were they; do certain topics receive more attention; and are some topics limited to one type of media over others?
The Tahdon2013 campaign (transl. Equal Marriage Law campaign), was a Finnish campaign started in 2013, which aimed to introduce an equal marriage law to Finland through a citizen’s initiative (käännös; kansalaisaloite). The campaign was successful and in 2014, the equal marriage law was voted on and accepted into Finnish law. The citizen’s initiative was challenged by another one much later in 2017 by another campaign that attempted to “protect the sanctity of marriage”, otherwise known as the “Aito Avioliitto” campaign (transl. True Marriage campaign).
With these questions in mind, our group set out to answer them through multidisciplinary approaches and the early progress we made was really good and our research questions all seemed to be highly relevant to the data we had access to during this project. Some of the questions however quickly eclipsed others in scope and we started focusing on certain topics over others, which meant that we weren’t able to produce the necessary datasets that we would have needed to analyse the differences between the trans law campaign and the Tahdon2013 campaign. There were some links between the two that we discovered, mainly focused on the transition and calls for the Tahdon2013 campaign to keep its momentum and shift its focus to the trans rights issues in Finland. But because the other research questions and queries that we ran in order to collect our larger data samples ended up taking longer than expected, we simply didn’t have the resources during the 10-day period to collect and analyse the data. Measuring things like the polarization of the discussion based around these campaigns was also cut short due to our need to utilize external tools and files, which proved to be a challenge to get to work within our internal systems.
- Our Approaches
Despite these setbacks, we managed to partially answer some of our research questions, and analyse large swathes of data from both social and traditional media and see how much social media is influenced by traditional media without there being a noticeable impact the other way around. The goal of the Tahdon2013 campaign was spoken about extensively within traditional media, most often focusing on the political and religious aspects of the debate, with some celebrities or politicians offering their public endorsements through traditional media, or simply offering party statements on the topic and how a particular political party positioned themselves on the issue. We quickly discovered how certain individuals generated large amounts of data based on their opinions or views on the matter, but that this didn’t necessarily mean that they should be the focus of our study.
All of us found it very easy to work within the group, and the interdisciplinary work that we did felt natural to many of us, and even if some of us weren’t very proficient in coding, listening to the ones who did understand coding at a deeper level, helped the group members who are in the humanities fields, understand their thought processes better. This also worked the other way around, where some of the data scientists or computer science students learned from the qualitative analysis processes that the humanities students partake in more frequently. A lot of people felt that it was more rewarding to collect our own data sets and then work on it afterwards, compared to being provided a static data set that we cannot modify or expand upon and that we would definitely do it again.
- Our Results
From our pre-collected and collected data, we had access to news journal articles from 1992-2020 and access to a large quantity of tweets that we had to gather ourselves, ending up with somewhere between 350,000 – 450,000 tweets in total from all of the queries that we made. We were primarily interested in the 2010-2017 period as that was the timeframe where the Tahdon2013 campaign and its counter campaigns were most active, while also keeping most of our dataset whole, as some of our news data only extended to the year 2017. We parsed our data with keywords list that we refined over the course of the Hackathon, unpacking the tweets that we gained and extracted the URLs from them in order to create links between social media activity and traditional news media in order to see what was being discussed on social media the most. Along with these, we qualitatively assessed a lot of our results when we couldn’t gain any more relevant information from our dataset when looking at them from afar.
A) Measuring the influence and power of actors
This brings us to the question we presented early on in our project about the actorship and measuring the influence and reach of certain actors, whether they were political parties, citizens campaigns, or single individuals. We measured their reach based on how many followers they had, how often their tweets were liked, and how often they were retweeted, placing a priority on interaction with the accounts as a sign of general reach:
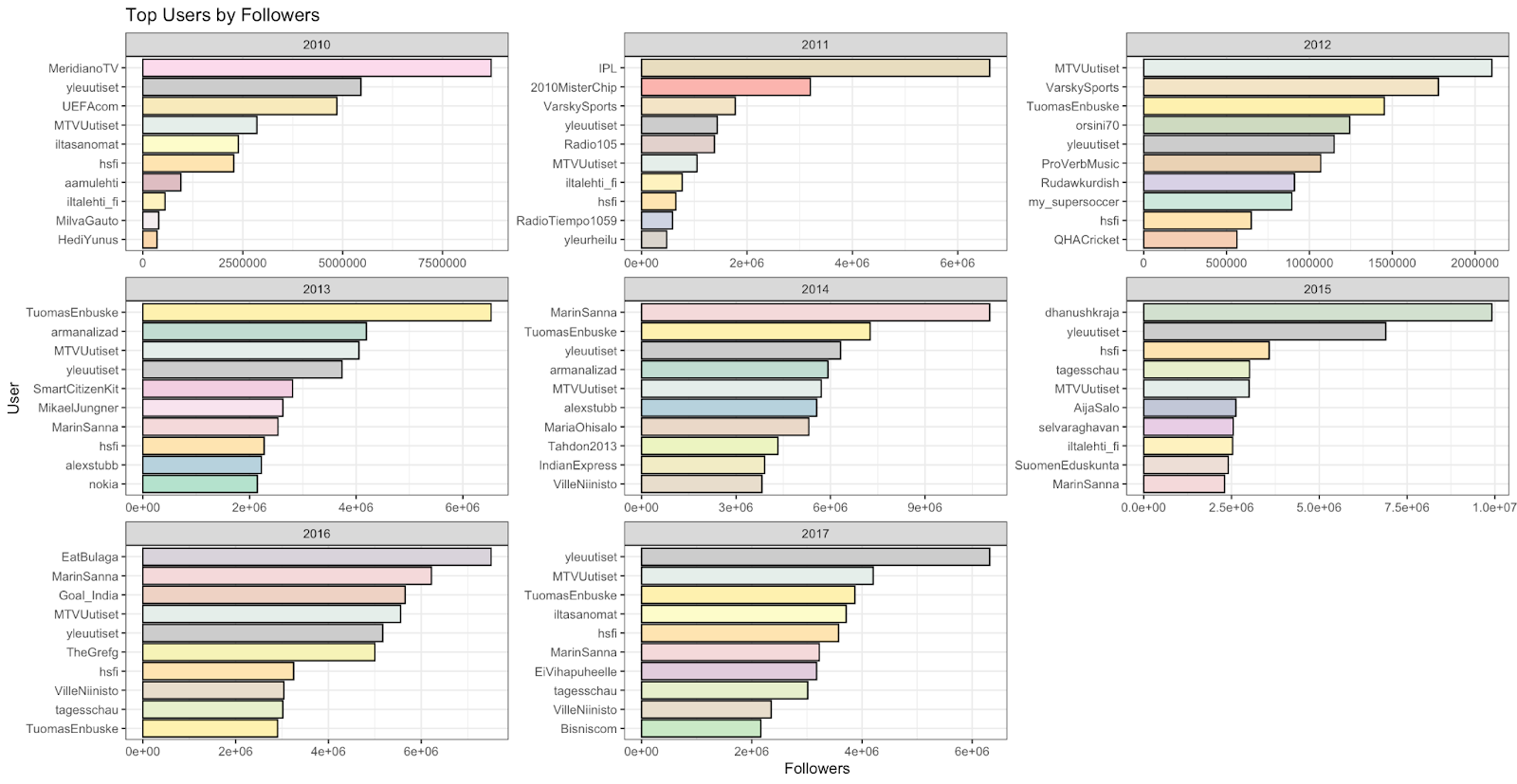
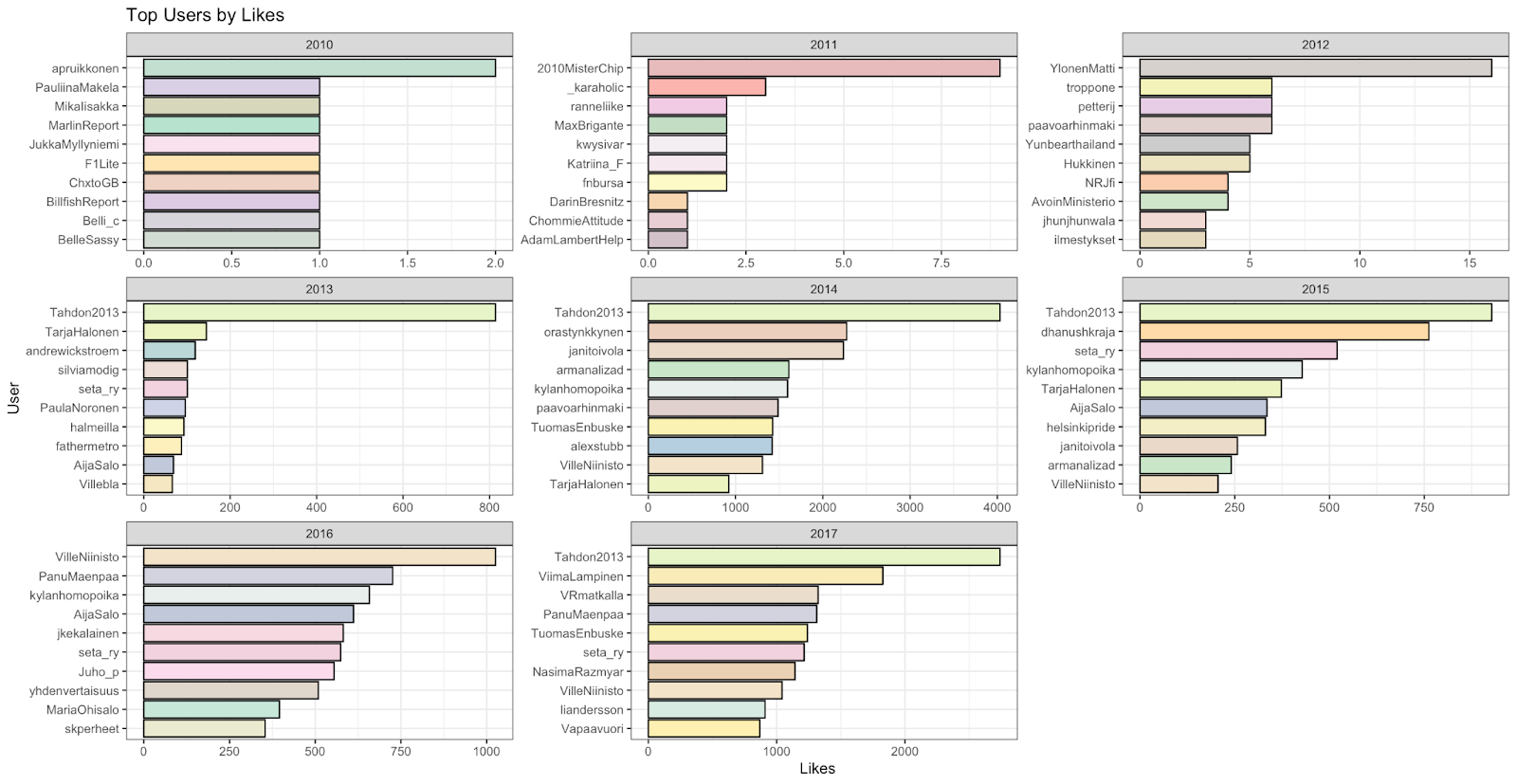
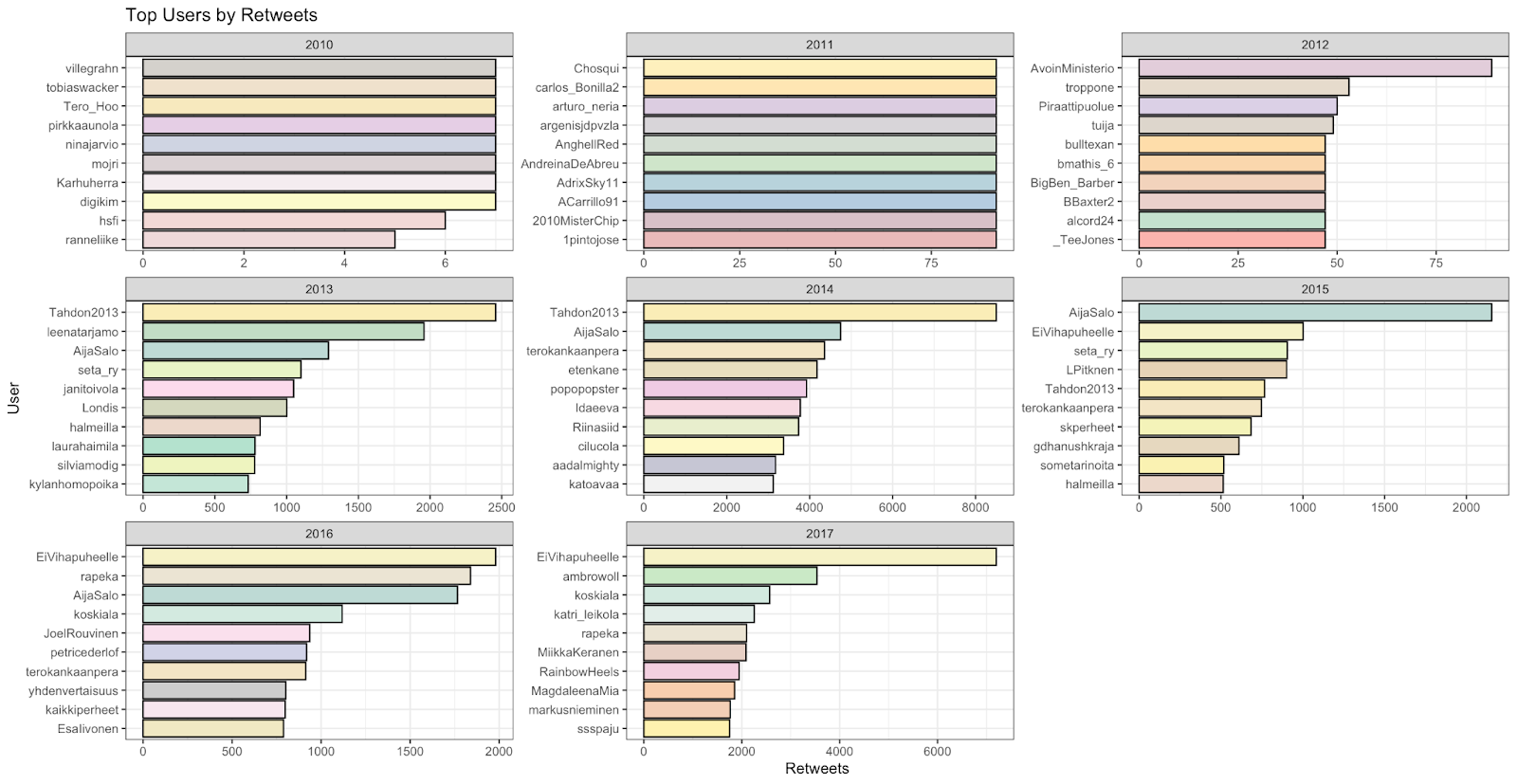
With these examples, we see that a considerable amount of Twitter users interacted with the official campaign account very frequently, and that certain politicians or social media personalities made a very large impact on social media based on certain months. From this data, we can infer that many of the active actors that were highly visible to the campaign, may not necessarily been more than a brief talking point in the grand scheme of things, leaving traditional political entities and the campaign organizers themselves as the most powerful actors within this campaign. This however showcases one of the problems with gathering data from Twitter; if the social status of an individual changes, or that they become more recognized by a larger community, such as a local politician becoming the prime minister, it heavily affects their visibility when analyzing past events. In this case, we see that the current Prime Minister of Finland, Sanna Marin, has received a large influx of followers since the Tahdon2013 campaign and this proves to be something that we cannot correct through any conceivable method since Twitter does not store historical data on its users.
This in itself leads to some problems that we will discuss in detail later, but Sanna Marin’s follower count is not representative of her status back during the campaign, as she has since taken on a more politically charged role and gained a large influx of followers.
We produced some visualisations on which parties who talked and were talked about the most, and contrasted those numbers with the number of representatives the parties had in parliament at the time, and measured their impact using the following criteria: number of representatives, number of tweets relating to the party, and the result of the campaign. Our data measured the amount of times that the party was either mentioned directly, or indirectly and from that data, we used more qualitative methods in order to identify the shortcomings of our data and interpret it to the best of our abilities.
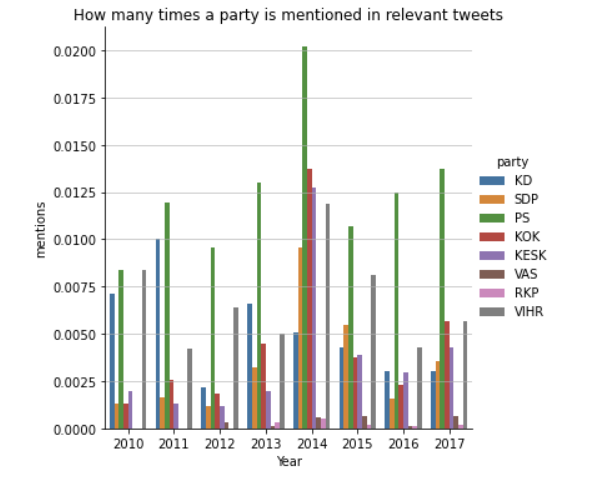
Keeping these spikes in mind, especially around the year 2014, we can determine that Kokoomus ended up being the primary source of discussion, as their internal party vote on the matter was split, which generated a lot of responses online, both for and against the party. Based on the final results, it is clear that if the party had made it an official policy to reject the motion, the law would not have passed. In contrast to this large influence, we can see several smaller and larger parties also be present in the Twitter discussion, and it would appear that certain smaller parties had more influence during the campaign despite being significantly smaller than the major parties at the time. This could be caused by the physical location of the supporters which would need to be analysed further in the future.
B) Peak data analysis
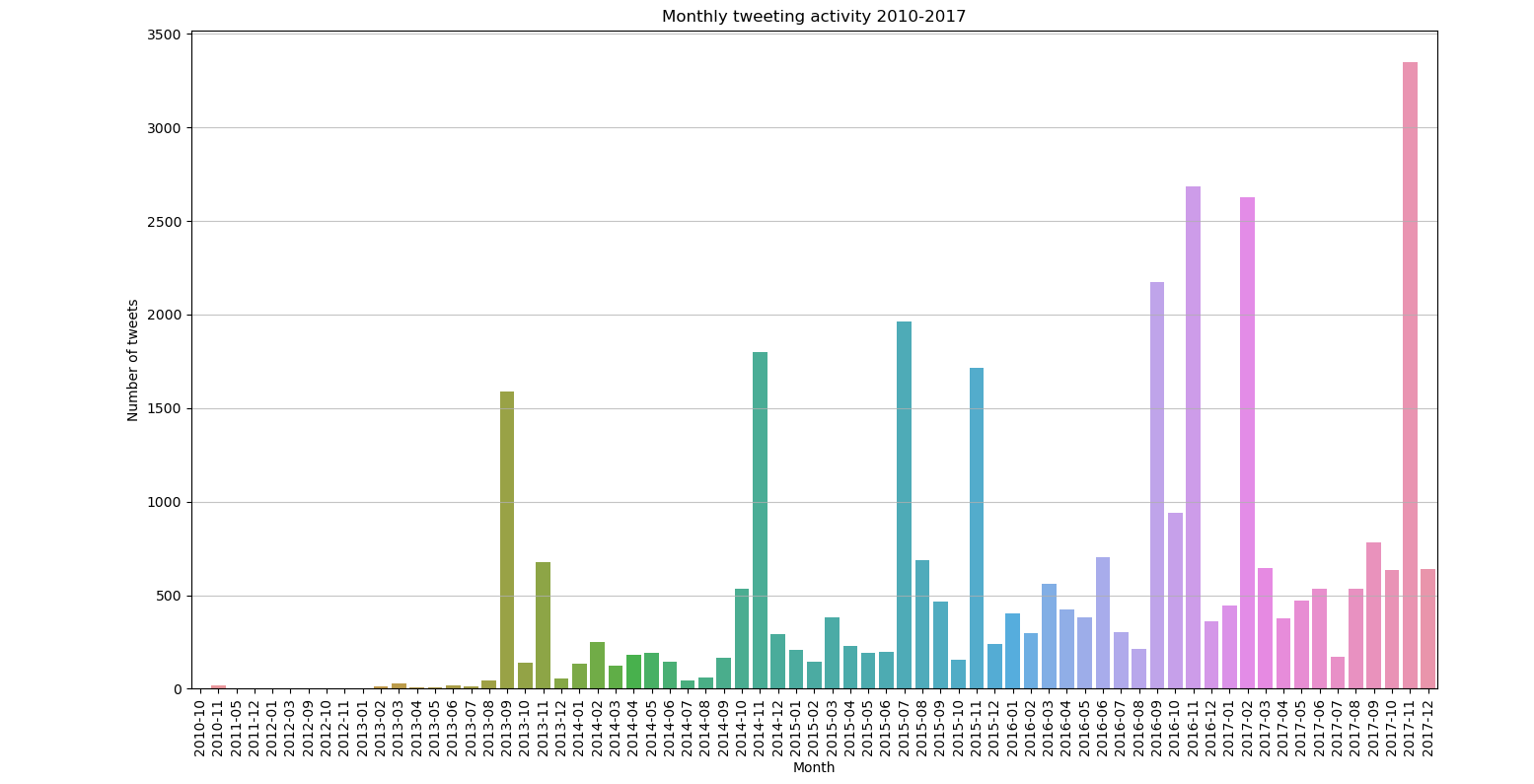
Our peak data analysis began with looking at the Tahdon2013 campaign and its counter campaigning between the years 2010-2017, identifying when the campaigns and their followers were active on Twitter. With our queries and results, we produced several charts on the tweeting activity frequencies, which we identified as showing the key moments in the campaigns. We made observations on them and noticed that the largest quantities of tweets were generated on days when physical events on the campaign were taking place, such as the time when the individual initiatives were launched, when the initiatives were first discussed in parliament, and finally when the initiatives were voted on within parliament.
Tahdon Campaign:

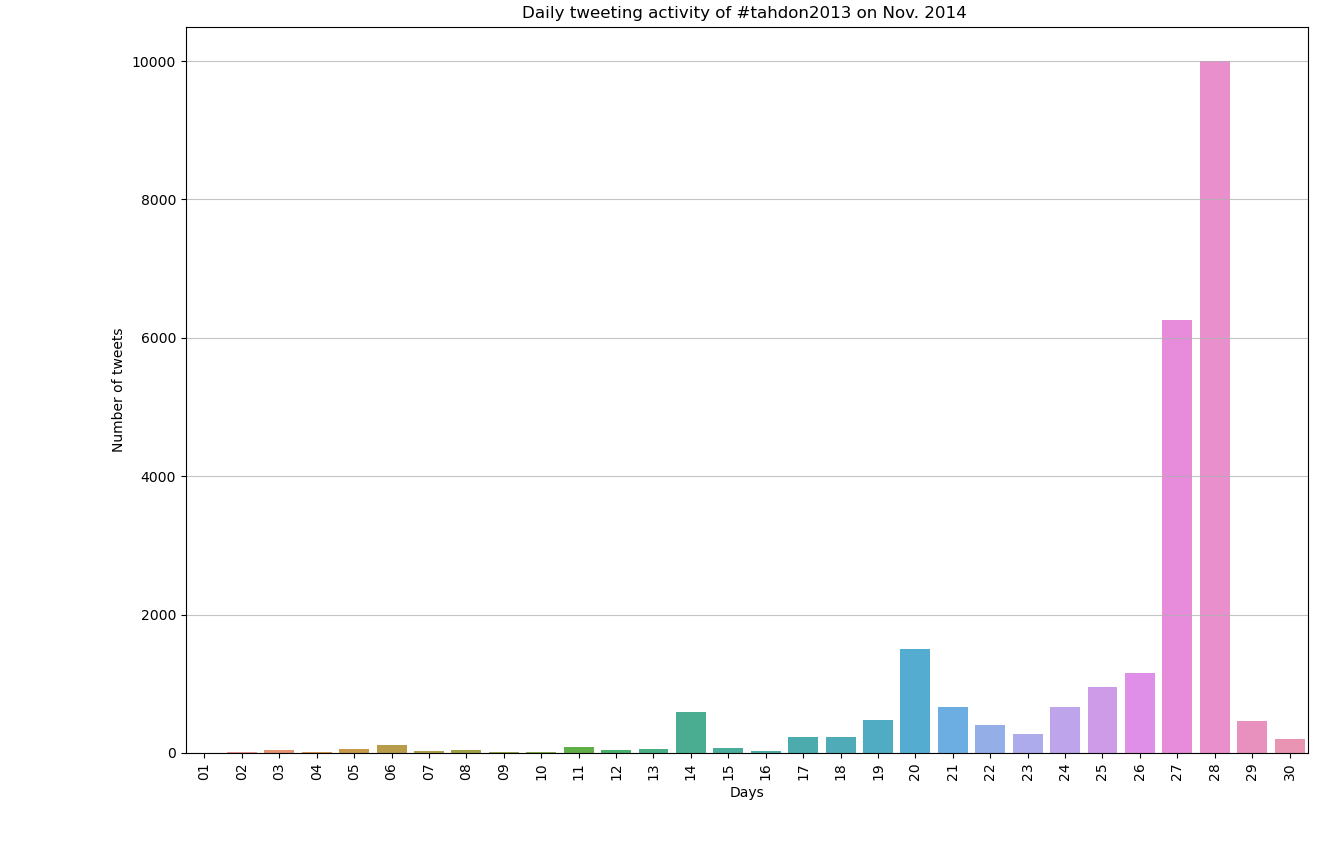

Counter Campaign:


While working with the keywords, we had a lot of data concerning what people on social media were talking about, but when we started producing our first data visualisations, it became apparent that not everything could be included. Here is an example of what happened when our collectively agreed upon our keyword list, which included the surname of a prominent counter campaign politician:
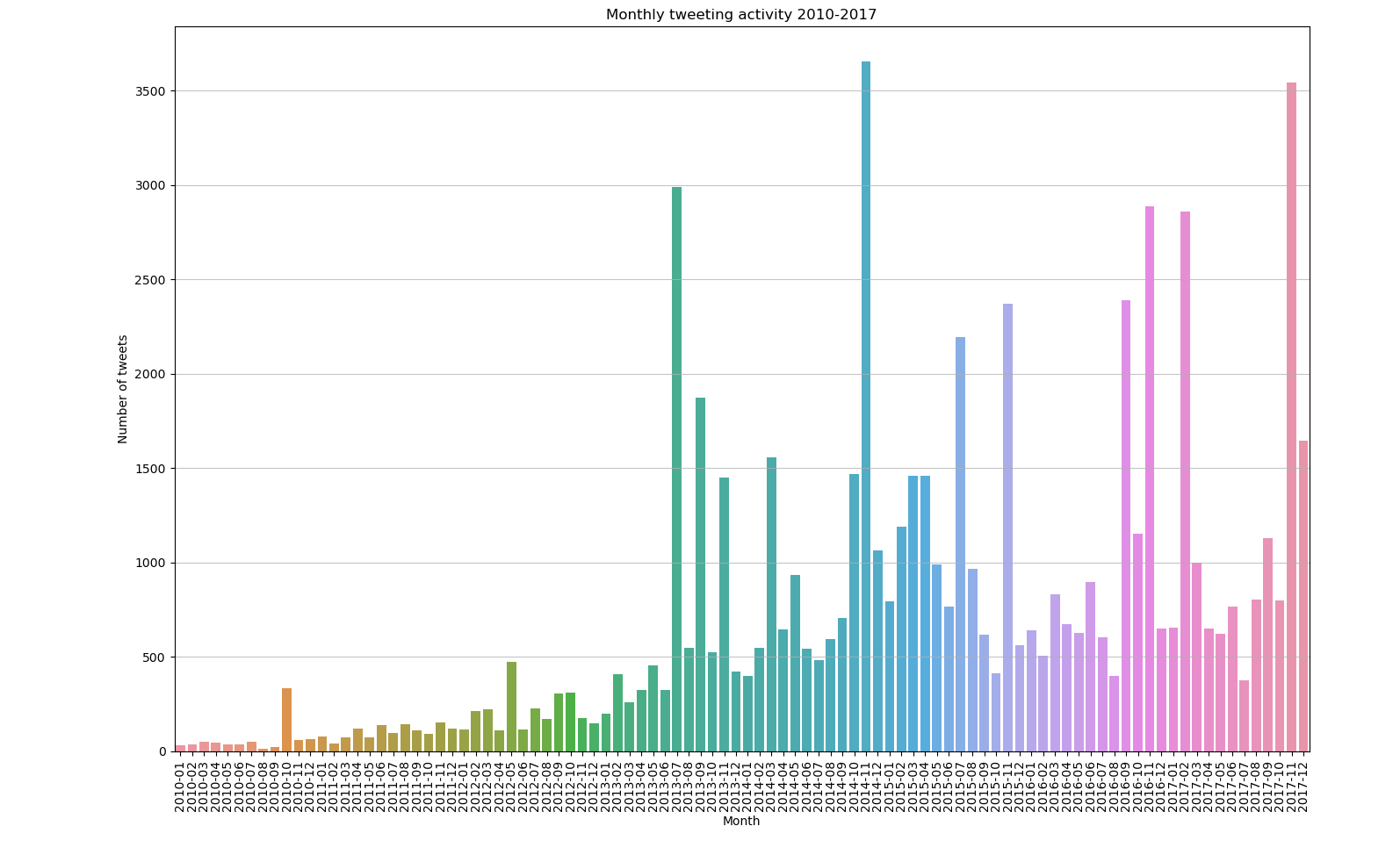
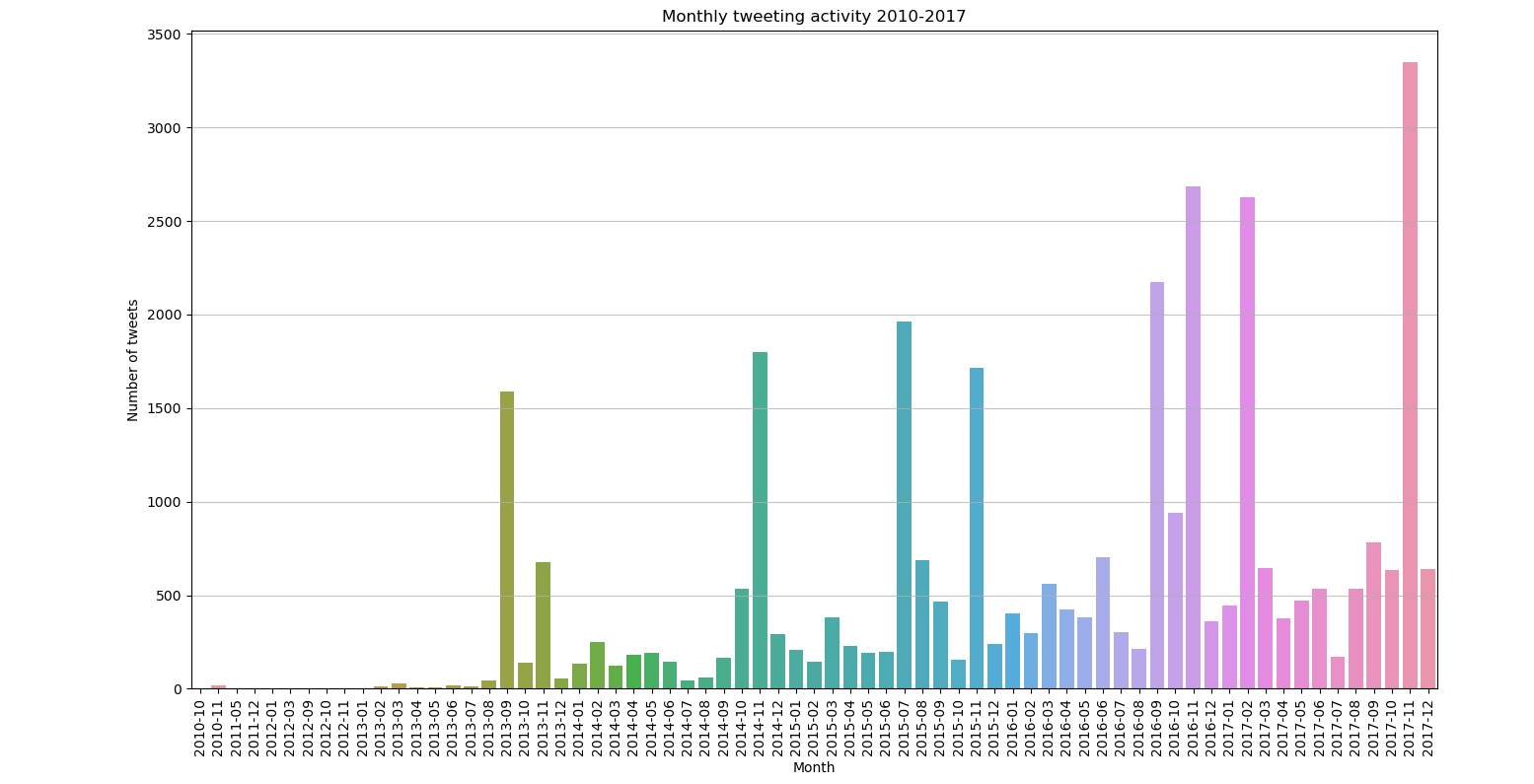
When looking at these graphs of the same time period, with and without the politicians surname, certain actors within campaigns like these, isn’t always indicative of why they are talked about a lot, and are more telling of their status within the political discourse. We adjusted our plans based on this and produced the graph after it without including their surname in the query itself rather than striking their name from the data in general, and we can see how visible the counter campaign was during the original campaign, and when the counter campaign was made into an official entity that opposed the equal marriage act.
C) News data analysis
Our efforts concentrated mostly on work with Twitter data and analysis of the news journalism did not progress very far. We experimented with a keyword based search that sought to capture relevant news articles by identifying a relatively long list of specific keywords. The keywords included the campaign names (like Tahdon2013), their articulated aims (tasa-arvoinen avioliittolaki ‘equal marriage act’) and relevant NGOs (eg. SETA ry, ‘LGBTI equality’).
In addition, we made use of bigrams that explicated some of the conceptual positions intrinsic to the debate about these topics. They included once related to the concept of marriage (“define marriage”, “concept of marriage”) and articulated specifications that marriage is a relation holding between particular groups (“marriage between”).
In general, the number of articles discussing the equal marriage process followed familiar dynamics from twitter discussions, peaking at the end November 2014 when the legislation passed.
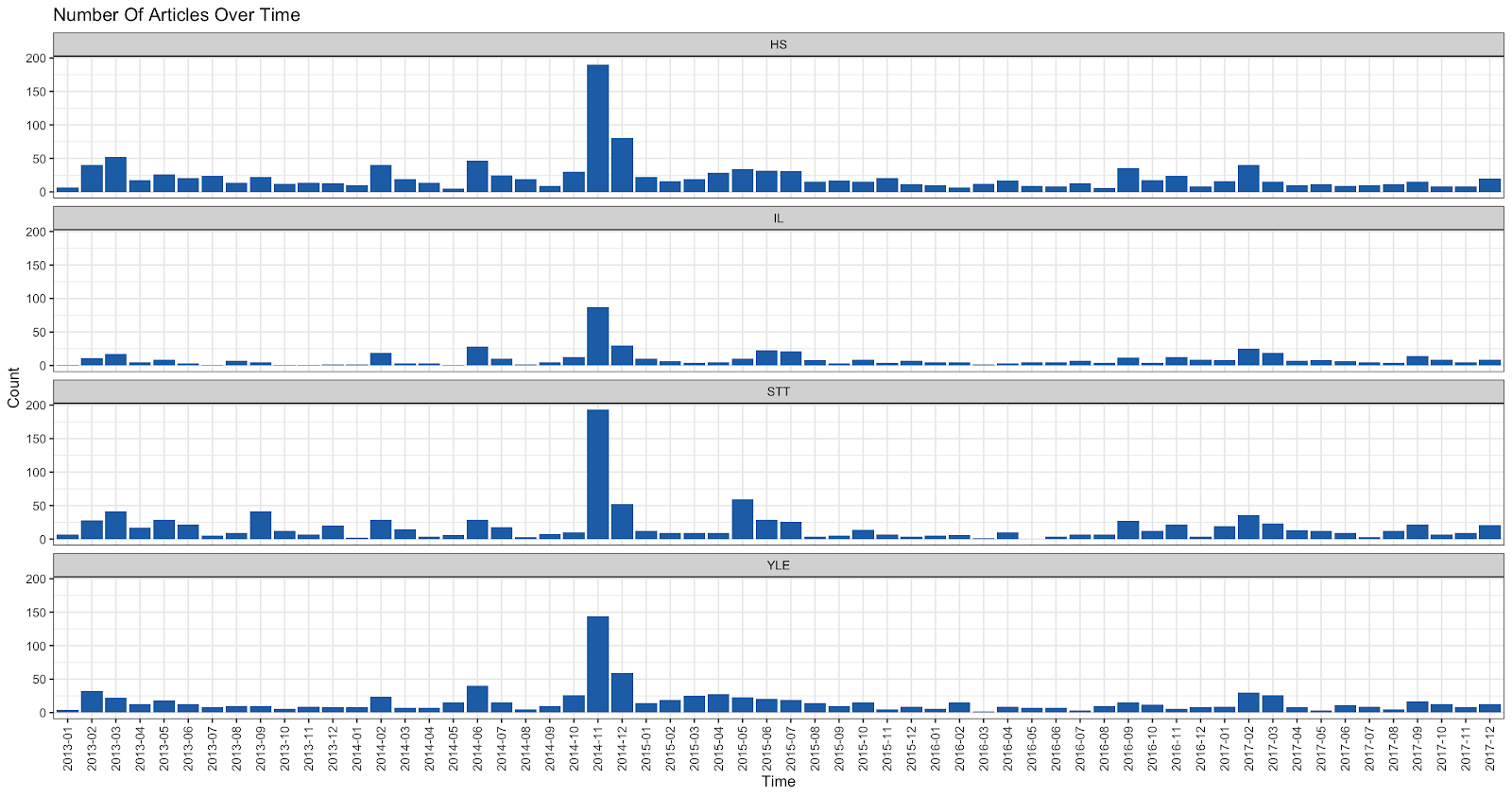
Relatively highest peaks are shown by Helsingin Sanomat and especially the tabloid Iltalehti. Compared to these public broadcast companies YLE has less articulate peak and news agency STT has the least. This seems to correspond well with the preliminary expectations, according to which YLE showed some hesitancy towards reporting the issue.
We managed to have tentative results on the amount of “love speech” in news media, which can be seen as a kind of a proxy variable for traction of the articulated communications strategies of the Tahdon2013 campaign.
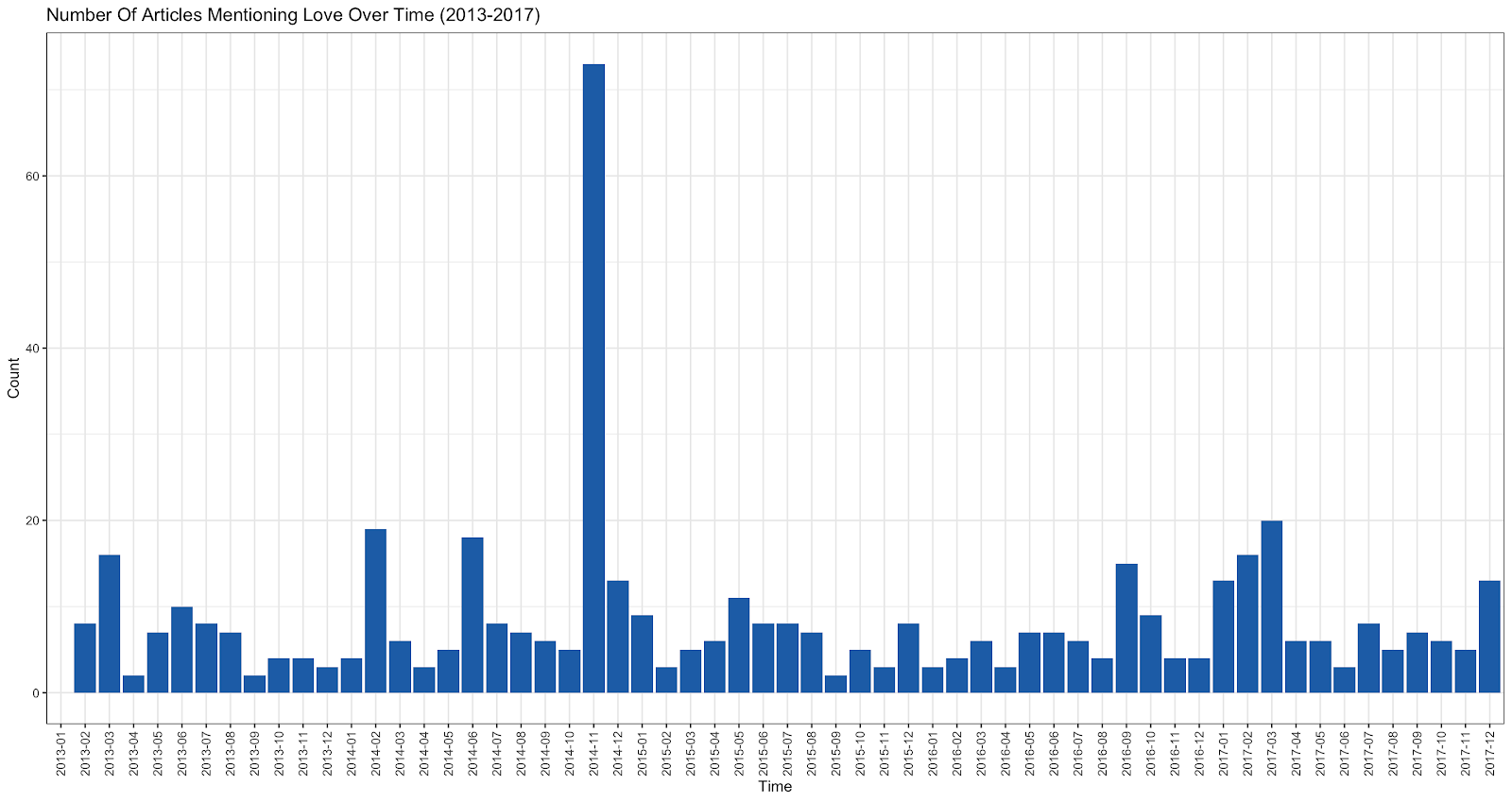
When the monthly count of articles mentioning the central love words (rakastaa, ‘love’, rakas ‘dear’, rakkaus ‘love’) is aggregated across the news sources, the peak in November 2014 is pronounced. This can be taken as a preliminary observation that the communication strategy of Tahdon2013 had traction in news media, not just Twitter.
We also looked at how much activities in Twitter in general were acknowledged and reported in the news media. Again, we have the same peak showing in November 2014, which seems to point towards the observation that the equal marriage campaign and the passing of the law was reported as a kind of a social media event.
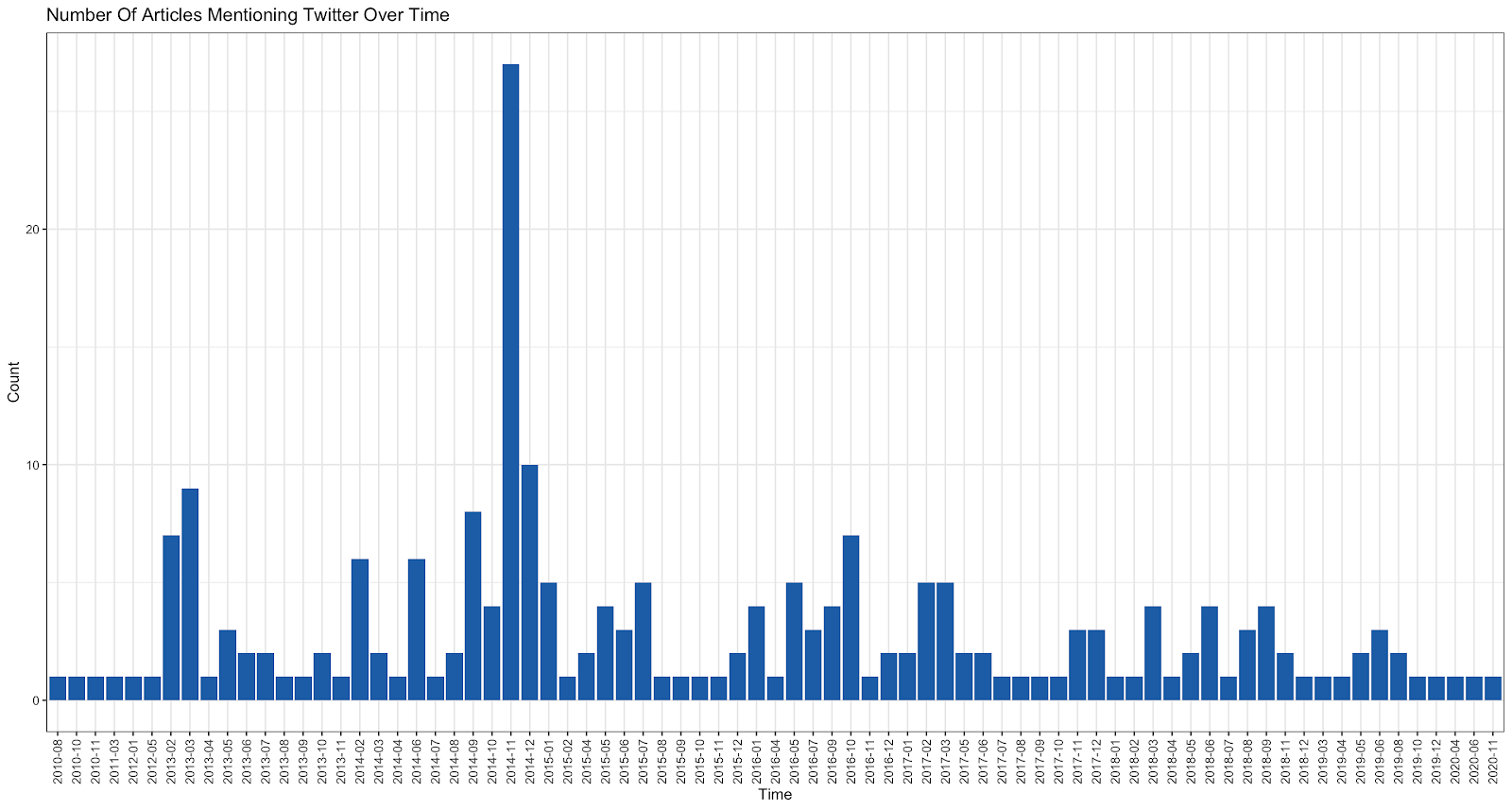
Articles mentioning Twitter discussion
- D) Component analysis
Looking into the tweets under the Tahdon2013 hashtag, we found there to be 52 modularity components. In our case, these components were linked together by retweets; either sharing a few tweets from a popular user or just one specific tweet. Definite similarities between the retweeters of a component were not easy to find, but the network revealed whose Tweets were considered worth sharing, and in which context. The absence of counter-campaigning in the tag came to the fore again, as only nine of the groups were not directly supporting the campaign. Provocative jokes and ambiguous expressions were present, but any actual hate speech did not pop up.
The content of the tweets can be divided into two groups: political statements and informative tweets, the first of which contains addressing counter arguments, building political pressure, humourous content and celebration. Informative tweets consist of links to articles and reports of current happenings, such as event times or voting results. Through these groups, and especially subgroups, it was possible to make some rough classifications. To give an example, in contrast to more straightforward supportive tweeting under the tag, there were groups that focused on sharing humorous content and misusing the #tahdon2013 tag, as well as groups that were more serious in tone, demanding the level of attention that this citizens’ initiative enjoyed to other social issues. In addition to topics, the speech style between the components also varied. In some groups a more formal style of speech was practiced, in others colloquial expressions and, for example, swear words were more popular.
| Component number | User account | Amount of retweets |
| 0 | @orastynkkynen | 13 |
| 1 | @tahdon2013 | 54 |
| 2 | @TarjaHalonen | 17 |
| 3 | @TuomasEnbuske | 16 |
| 4 | @seta_ry@janitoivola | 3221 |
| 5 | @VilleNiinisto | 30 |
| 6 | @titmeister | 52 |
| 7 | @paavoarhinmaki | 46 |
| 8 | @vihreat | 45 |
| 9 | @laurahaimila@lassemannisto | 3824 |
| 10 | @fathermetro@AslakBB | 3718 |
Finally, it was interesting to see how companies’ involvement in the campaign was reflected on Twitter. For instance, certain companies, like Elisa, DNA, Reaktor, Kiasma and Universal Music, published tweets either from a company account shared by employees or expressed their support for the initiative through employee accounts. This fits well with the previous research done on how corporate participation in the campaign was not only a political statement but also an economic investment.

- E) Sentiment analysis
In our group, we also produced some early looks at the sentiments found within the Twitter data that we had, and we produced several graphs on the love speech found during the campaign on Twitter:
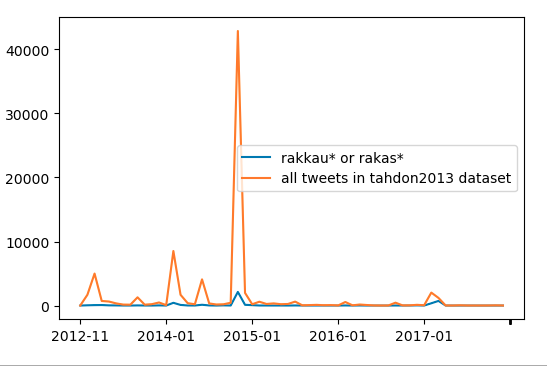
Despite our assumptions, the frequency of love speech during the campaign was quite minimal in the end. Even with hashtags such as LoveWins etc., we didn’t see a large number of users participating in those hashtags.
Another approach to sentiment analysis utilized the Finnish FEIL lexicon created by Emily Öhman in her dissertation. This lexicon has some serious shortcomings and thus the reliability of the sentiment analysis is questionable. We are hoping that aggregating over a large number of tweets evens out some of the anomalies. Furthermore, we gathered a reference dataset of random tweets from the same timeline to act as a baseline and looked at how the emotions generated by our data differ from that baseline. Below is depicted how the intensities of seven emotions tracked vary during years 2013-2014 in our dataset. All values are corrected with regards to the base line.
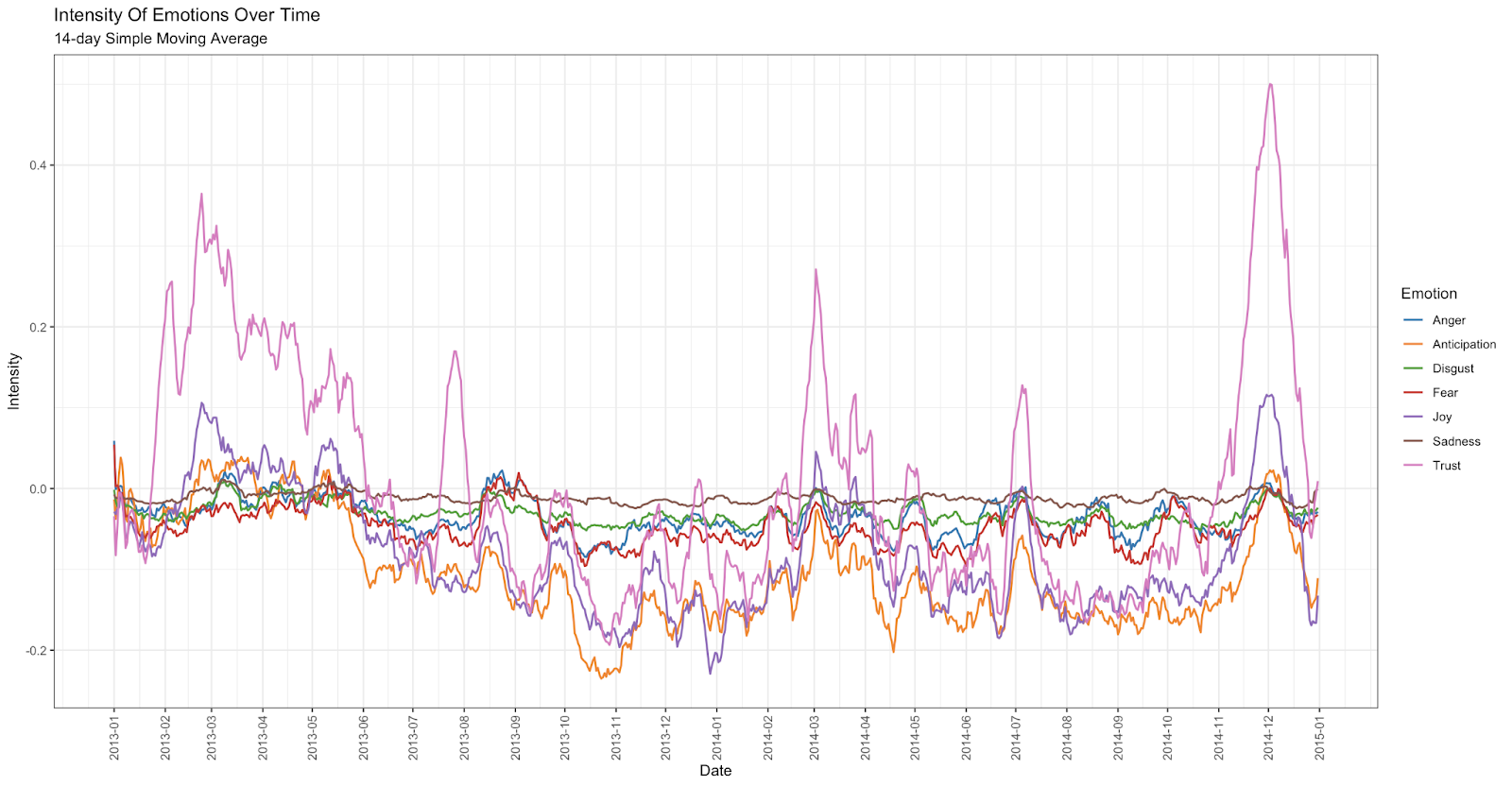
There are clear peaks in affectivity, which correspond with the key events of the Tahdon2013 campaign, most notably when the Marriage Act passed at the end of 2014. The scale of the emotions is not comparable across different emotions. We thought about whether to normalize these, but decided to leave them as they are. The differences between emotions might to some extent be explained by just the lexicon being used.
F) Measuring polarization
We approached the polarization of speech by studying the number of nationalistic terms and feelings expressed in the tweets on two specific days that the Tahdon2013 tag was most actively used during the year 2014. The most active day was the 28th of November when the citizen initiative was voted on in the Parliament and the second most active day was the 20th of February when the initiative was addressed in Parliament.
Based on the tweets we gathered from these two days, we examined the nationalistic and often global pressure created by the choices of words and terms. For example, terms like the modern age, western- and northern countries, civilization, were used to persuade the other side. In addition, values like equality, tolerance, and human rights were heavily used. We were interested in the polarization of speech during significant or exciting events in regards to the citizen initiative. We found that patriotism was present in speech, from all through February but the amount increased significantly when the time to vote got closer and after the results were published.
The emphasis on Finnish nationality was an interesting phenomenon as during other societal issues it is often used actively by the conservative side. This, alongside with other less organized tweets addressing counter-arguments, would suggest that the Tahdon2013 campaign was well organized, as it systematically made possible counter-arguments a part of the campaign and its proposed view of the world.
| 20.2.2014 | 28.11.2014 | |
| kiitos | 97 | 230 |
| rakkaus | 120 | 289 |
| suomi | 43 | 301 |
| suomalaisuus | 15 | 61 |
| sivistys | 3 | 38 |
| länsi | 3 | 15 |
| suvaitsevaisuus | 28 | 20 |
| ihmisoikeudet | 90 | 45 |
| yhdenvertaisuus | 28 | 33 |
| tasa-arvo | 260 | 360 |
- Current Challenges
As discussed previously, we were presented with some unique challenges as all of us worked with Twitter data for the first time. With the example of Sanna Marin that was mentioned previously in the actorship results, Twitter’s data is very much incomplete for our purposes. Any deleted tweets, accounts, or updates to accounts and their increased general traffic, means that the data loses some of its accuracy. If a politician used to be a member of a different party at the time, it will create inaccuracies in our results. There is no real way of reconciling the data in this sense since there is no way to get historical data from Twitter itself, which leaves parts of the data very inaccurate if we wanted to analyse it more, because the popularity, occupation, and political leanings of individuals changes drastically over time.
We also faced challenges with fitting pre-existing tools and inputs into our own systems due to a lack of understanding of those systems, such as the NLP pipelines, that proved to be very difficult hurdles to overcome, and even more difficult to interpret as we produced our first results from them. With more time, we would probably have developed our own tools and methods in dealing with these challenges so that we would have more control over the process, but that was simply not possible during a 10-day period. This meant that our sentiment analysis ended up being very bare in the end, and the results left us somewhat ambivalent on what we could actually gain from them. This problem of using pre-made tools somewhat extended over to a lot of other things as well, since we didn’t really have a virtual platform to perform coding on, meaning that only those with a ready-to-go system could perform the coding tasks. On top of this, trying to learn a new tool that uses a very specific query method provides some very unique challenges, especially when crossing over from english documentation and trying to apply some of the measures they discuss into finnish language.
One thing that was surprisingly difficult to track down in this project was the counter campaigning against the LGBT rights campaigns. In recent years, there has been a stronger online proponent into objecting LGBT positive legislation and movements, but going back several years gives us links to events that take place in the real world. This makes it far more difficult to track the evolution of counter campaigning as we don’t have an accurate timeline of what has been happening without having access to a deeper pool of data from websites that track events that oppose certain movements. We produced a very extensive list of counter campaigning terms, but they only produced a fraction of the results that the campaign terms did. This was touched upon when we discussed the influence of controversial figures on our data, and how including them in the counter campaigning terms nearly tripled the results we received, which prompted us to adjust our approach immediately.
- Our Plans for Future Research
We as a group felt that the best way of moving forward with the research would be to make sure that everyone had initial input on what type of results they would like to end up with during the project. We would also have liked to work on more tools of our own rather than rely on borrowing the work of others without having an in-depth knowledge on how it works that even reading through documentation can’t really give us.
A lot of us also felt that given the time restrictions, we weren’t really in a place to give the trans law campaign a fair treatment, and a lot of our work was put to the side when just working with the Tahdon2013 campaign material proved to be more time consuming than we had initially thought. And while we progressed incredibly quickly at the beginning when making multiple keyword lists, we had difficulties in finding time to refine them alongside our plethora of other tasks.
Thank you for joining us on this DHH21 Hackathon and good wishes from the FloPo team:
Pihla, Antti, Juhani, Olavi, Henni, Alma, Dara, Timo, Eliisa, and Riikka
